175M+ ethically sourced IPs built for the highest reliability.
High-speed, cost-effective proxies built for any scraping workload.
Premium static residential proxies from trusted ASNs for most difficult targets.
Dedicated IPs from premium ASNs for demanding scraping.

AI-powered proxy solution for optimized web scraping performance.

20M+ IP addresses from real mobile devices for precise targeting.

Free Chrome proxy manager extension that works with any proxy provider.

Free Android proxy manager app that works with any proxy provider.

Free community-driven tools to improve your web scraping projects.
Web Scraper API
All-in-one web data collection platform for every stage of web scraping.
Fast Search API
Ultra-fast organic search results scraper tailored for AI workflows.
Headless Browser
Advanced browser automation solution for AI agents and scraping.
AI Studio
A suite of AI-powered tools for various scraping projects.

Documentation
All features, parameters, and integration details, backed by code samples in every coding language.
Tutorials, samples, and guides.
Latest fixes and features.






![]() AI Summary:
AI Summary:
Web scraping with Ruby lets you automatically collect publicly available data from websites. For static pages, you can use the HTTParty gem to fetch a webpage's content and Nokogiri to parse the HTML and extract the data you need with CSS selectors. For dynamic pages that load content with JavaScript, Selenium WebDriver can handle the job by running a headless browser. In both cases, the extracted data can be saved to a CSV file for easy use.
Web scraping, also called data scraping, is rapidly becoming a must-have tool for companies around the globe. While data collection and analysis are practices known to most businesses, it may be a complete novelty when it comes to collecting public data using web scraping techniques. As one of the web scraping solutions, Ruby can efficiently handle the whole spectrum of web scraping related tasks.
Ruby is a time-tested, open-source programming language. Its first version was released in 1996, while the latest major iteration 3 was dropped in 2020. This article covers tools and techniques for web scraping with Ruby that work with the latest version 3.
For your convenience, we also prepared this tutorial in a video format:

We’ll begin with a step-by-step overview of scraping static public web pages first and shift our focus to the means of scraping dynamic pages. While the first approach works with most websites, it'll not function with the dynamic pages that use JavaScript to render the content. To handle these sites, we’ll look at headless browsers.
Installing Ruby
To install Ruby on Windows, download and run the Ruby Installer.
Alternatively, you can use a package manager such as Chocolatey. If you're using Chocolatey, open the command prompt and run the following:
choco install rubyThis will download and install everything you need to get started with Ruby.
macOS is bundled with Ruby version 2 by default. It's recommended not to use it and install a separate instance. Since the current release of Ruby is version 3, we’ll be using this version for the contents of this article. Nonetheless, the code that we’ll be writing is backward compatible with version 2.6 as well.
To install Ruby on macOS, use a package manager such as Homebrew. Enter the following in the terminal:
brew install rubyThis will download and install the Ruby development environment.
For Linux, use the package manager for your distro. For example, run the following for Ubuntu:
sudo apt install ruby-fullScraping static pages
In this section, we’ll write a web scraper that can scrape data from https://sandbox.oxylabs.io/products. It's a dummy video game store for practicing web scraping with static websites.
Installing required gems
A Ruby package is called a “gem” and can be installed via the command line. The first required gem is HTTParty. Its purpose is to get a response from a website. There are some other options, such as Net/HTTP, Open URI, etc. In this example, we’ll use HTTParty as it's one of the most popular mainstream gems.
To parse the website’s response, we’ll be using another gem — Nokogiri. Finally, to export the data as a CSV file, we’ll use the CSV gem.
To install these gems, open the terminal and run the following commands:
gem install httparty
gem install nokogiri
gem install csvAlternatively, create a new file in the directory where you’ll store the code files and save it as Gemfile. In this file, enter the following lines:
source 'https://rubygems.org'
gem 'nokogiri'
gem 'httparty'
gem 'csv'Open the terminal, navigate to the directory, and run the following:
bundleThis will install all the gems listed in Gemfile.
Making an HTTP request
The first step of web scraping with Ruby is to send an HTTP request.
When a page is loaded in the browser, the browser sends an HTTP GET request to the web page. This action can be replicated using HTTParty with only two lines:
require 'httparty'
response = HTTParty.get(‘https://sandbox.oxylabs.io/products')The first line is a require statement, which needs to be written only once. In essence, sending HTTP requests takes only one line of code.
The response object returned using this method contains many useful properties. For example, response.code contains the status code of the HTTP request. The HTTP status code for the success is 200. The actual returned HTML is contained in the response.body.
If you just want to take a look at the HTML of the response, add these lines to the code:
if response.code == 200
puts response.body
else
puts "Error: #{response.code}"
exit
endFor our web scraper, this particular HTML string isn't that useful, meaning that one more step is required to extract the specific information from this page.
At this moment, HTML parsing comes into play, represented by the Nokogiri gem.
Parsing HTML with Nokogiri
You can use the HTML4 module of Nokogiri to parse data in our HTML string.
Note that before version 1.12 of Nokogiri, the module HTML4 didn't exist. If you're working with an earlier version, use the HTML module instead. In fact, in the newer version of Nokogiri, you can still use the HTML module, which isn't just an alias for the HTML4 module.
The first step is to add the require statement:
require 'nokogiri'Next, call the HTML4 and send the HTML string. The string is found in the response.body:
document = Nokogiri::HTML4(response.body)This document object contains parsed data that can be queried using CSS Selectors or XPath to get specific HTML elements. In this article, we'll use CSS Selectors to locate the HTML elements.
We’ll be extracting three types of public data from our target website: title, price, and availability. First, we’ll create a selector for the container that holds all this information. Then, we’ll run a loop over all of these containers to extract data.
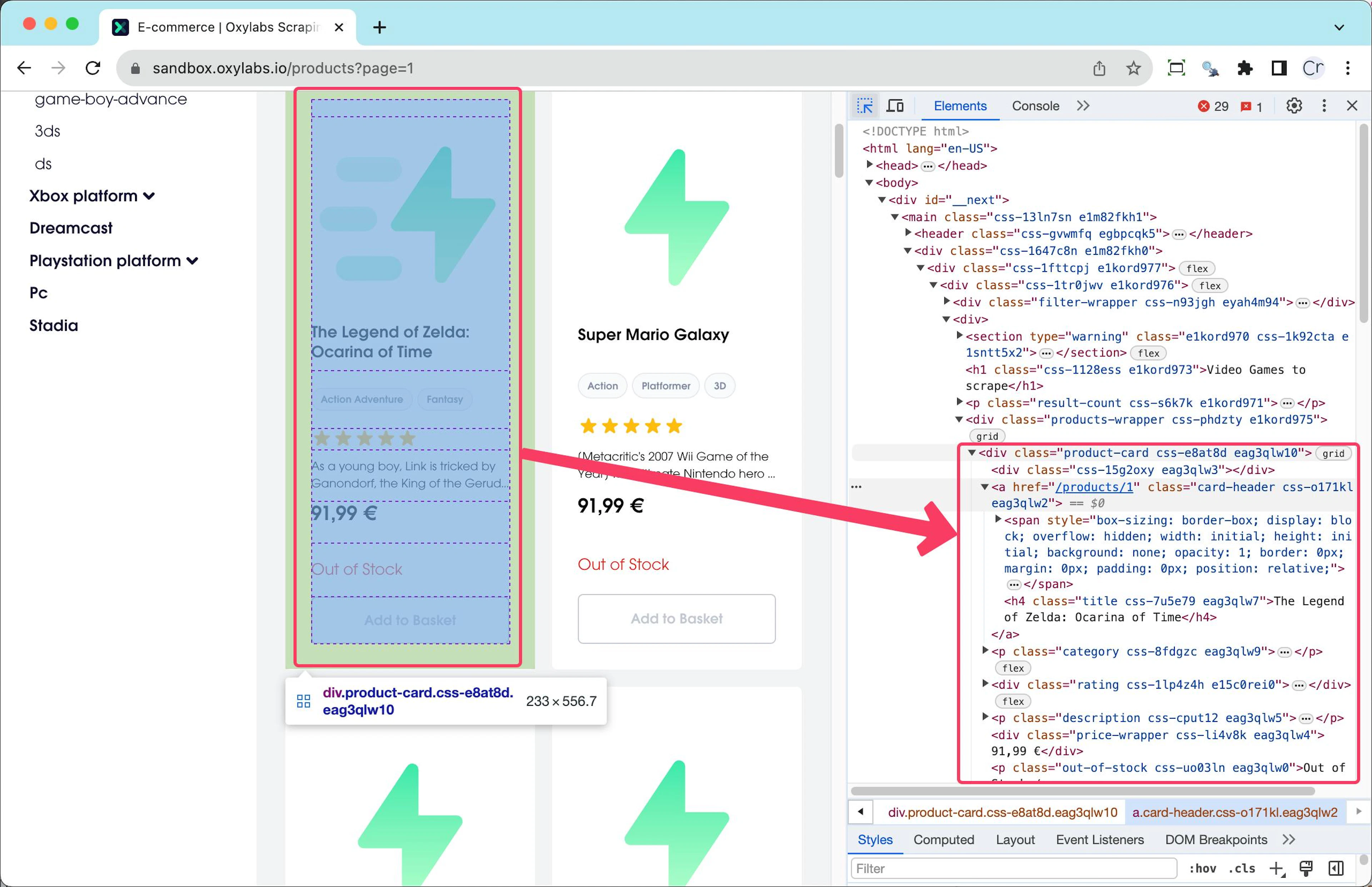
The video game container
Each game is contained in the HTML element div with its class set to product_card. Using this information, the following line of code will return all the game container elements:
all_game_containers = document.css('.product-card')The resulting element can be queried using CSS selectors to get the specific HTML elements in a loop:
all_book_containers.each do |container|
...
endThe title of the game is in the heading of the container h4, the most convenient way to retrieve it's as follows:
title = container.css(‘h4').text.stripThe .css() function returns an array. That’s why we need to take the first element and then retrieve the value of the alt attribute.
Extracting the price is easier as it's a text:
price = container.css('.price-wrapper').textIt will also return a currency symbol. The symbol can be easily excluded by using the delete function. The following will delete everything except the numbers and the period:
price = container.css('.price-wrapper').text.delete('^0-9.')Similarly, the categories can be extracted as follows:
category_elements = container.css('.category span')
categories = category_elements.map { |elem| elem.text.strip }.join(', ') Note the use of strip here. It will remove the line breaks and spaces.
The three fields that we have just extracted can be used to create an array, which in turn can be appended to another array. It means that at the end of the loop, all information will be available as an array of arrays. Here is the entire loop put together:
all_game_containers = document.css('.product-card')
games = []
all_game_containers.each do |container|
title = container.css('.image_container > a > img').first['alt']
price = container.css('.price-wrapper').text.delete('^0-9.')
category_elements = container.css('.category span')
categories = category_elements.map { |elem| elem.text.strip }.join(', ')
game = [title, price, categories]
games << game
endThe pagination for this site is a simple numerical sequence. We can see that there are 50 pages, and the URL of each page follows this pattern:
https://sandbox.oxylabs.io/products?page=1
https://sandbox.oxylabs.io/products?page=2
...
https://sandbox.oxylabs.io/products?page=50 Due to the uncomplicated sequence above, we can get away with a simple loop. The following is a code for the pagination:
games = []
50.times do |i|
url = "https://sandbox.oxylabs.io/products?page={i+1}"
response = HTTParty.get(url)
document = Nokogiri::HTML(response.body)
all_game_containers = document.css('.product-card')
all_game_containers.each do |container|
title = container.css('h4').text.strip
price = container.css('.price-wrapper').text.delete('^0-9.')
category_elements = container.css('.category span')
categories = category_elements.map { |elem| elem.text.strip }.join(', ')
game = [title, price, categories]
end
endWriting scraped data to a CSV file
After extracting data into an array of arrays, the CSV gem can be used to export the data.
Begin with adding the require statement to the code file:
require 'csv'The first step is to open a CSV file in write or append mode. While opening the CSV, it's also a good idea to write the headers.
To keep things simple, we can send an array of Title, Price, and Categories.
Finally, read the data and write it immediately to at least keep some chunks in the CSV file if a script fails mid-execution.
The following code puts everything together:
require 'csv'
CSV.open(
'games.csv',
'w+',
write_headers: true,
headers: %w[Title, Price, Categories]
) do |csv|
50.times do |i|
response = HTTParty.get("https://sandbox.oxylabs.io/products?page={i+1}")
document = Nokogiri::HTML4(response.body)
all_game_containers = document.css('.product-card')
all_games_containers.each do |container|
title = container.css('h4').text.strip
price = container.css('.price-wrapper').text.delete('^0-9.')
category_elements = container.css('.category span')
categories = category_elements.map { |elem| elem.text.strip }.join(', ')
game = [title, price, categories]
csv << game
end
end
end
That’s it! You have successfully created a web scraper with Ruby that can create a CSV file by extracting data.
Scraping dynamic pages
The approach discussed in the previous section using HTTParty works great when scraping public data from static web pages. However it isn’t suitable for dynamic pages. HTTParty gets a response from the request URL, but it doesn’t render the page, meaning that any data that's loaded separately isn't loaded at all.
There are multiple gems that can help solve this problem. One of the most popular gems for the task is Kimurai. However, Kimurai hasn't been updated yet and doesn't work with Ruby version 3.
Fortunately, the time-tested solution to run a headless browser, Selenium, works perfectly with Ruby. The official Selenium documentation has code examples in Ruby.
Required installation
To commence working with Selenium, install your preferred internet browser. The popular choices are Chrome and Firefox.
Once the browser is ready, install the selenium-webdriver gem following the instructions:
gem install selenium-webdriverAdditionally, if required, install the CSV gem:
gem install csvLoading a dynamic website
For this example, we will work with a dynamically rendered website https://quotes.toscrape.com/js/.
Before we can send an HTTP request to load the page, some initial setup is required.
First, add the require statement to the top of the file:
require 'selenium-webdriver'Next, create an instance of Selenium WebDriver for Chrome.
driver = Selenium::WebDriver.for(:chrome)Note that this will create an instance of Chrome that is visible, meaning that it will be a headed browser. It may be acceptable during the development, but ideally, you would want to keep the browser invisible or headless.
To make the browser headless, first, create an instance of Chrome::Options and set the headless to false. Then, send an instance as the options parameter as follows:
options = Selenium::WebDriver::Chrome::Options.new
options.add_argument('--headless')
driver = Selenium::WebDriver.for(:chrome, options: options)Finally, call the get method to load the web page:
driver.get 'https://quotes.toscrape.com/js/'The page is now loaded and ready to be queried for the HTML elements.
Locating HTML elements via CSS selectors
The HTML can be extracted using the driver.page_source method. If you prefer, you can use a particular HTML to create an object of the Nokogiri document as follows:
document = Nokogiri::HTML(driver.page_source)Selenium comes with its own powerful methods for querying HTML elements.
The function that will be used is find_elements. It takes either a css or an xpath parameter to locate the HTML element and return an array of all matching elements.
If you only need one element, there is a find_element variation of this function, which returns only the first matching element.
The overall approach of this web scraper will be the same as the previous one:
Locate the HTML elements that contain each quote using CSS Selector.
Run a loop over these elements.
Extract the quotation text and author using CSS selectors.
Create an array of each quote.
Append the array to an outer array.
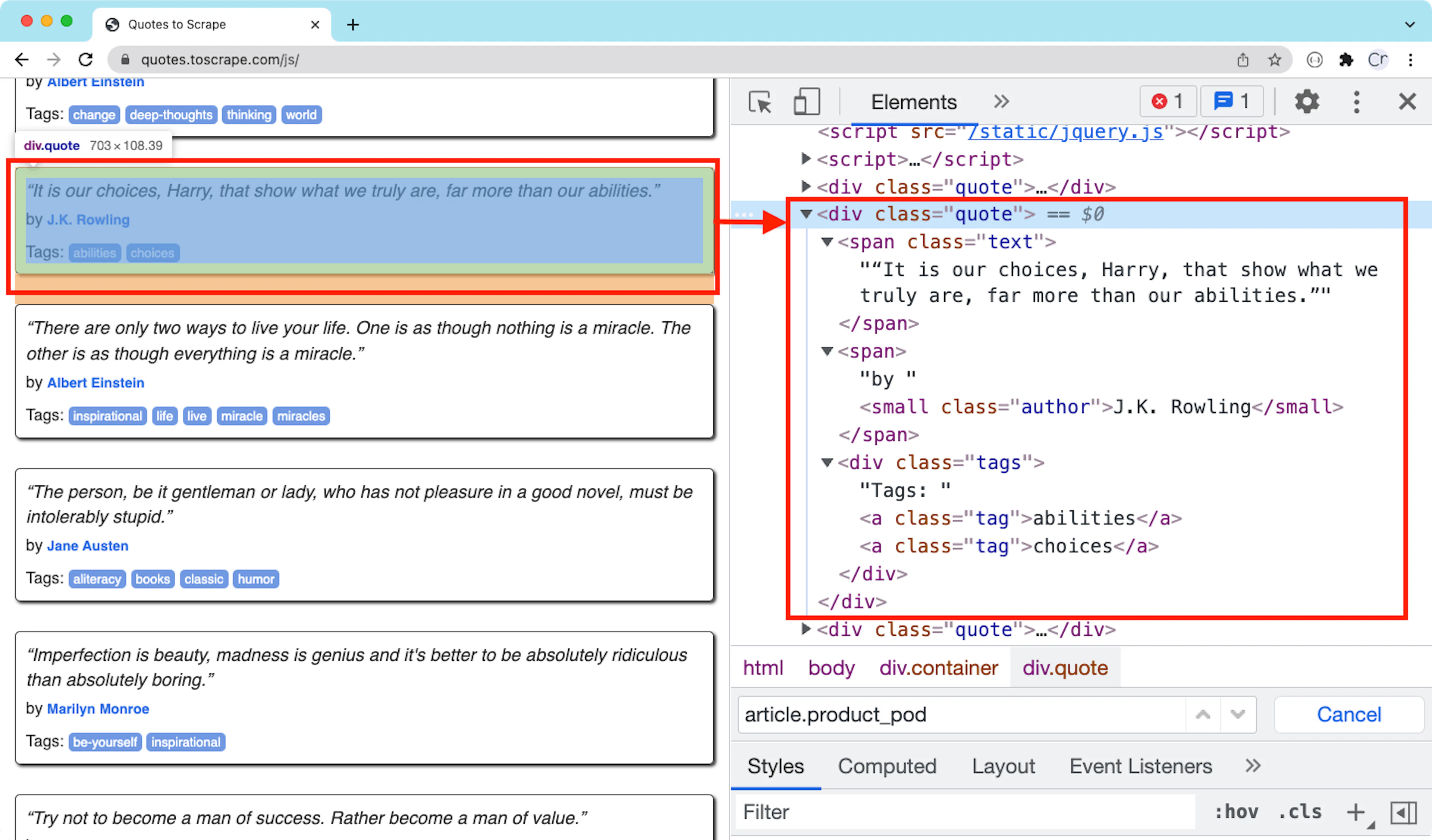
The container HTML element of a quote
Each quote is contained in a div element with a class quote. The CSS selector can be simply .quote. The first piece of the code will be as follows:
quote_container = driver.find_elements(css: '.quote')
quote_container.each do |quote_el|
# Scrape each quote
endThe CSS selector for the quote text is .text. To get the text inside this span element, we can call the attribute function with a textContent parameter:
quote_text = quote_el.find_element(css: '.text').attribute('textContent')Similarly, getting the author is also straightforward:
author = quote_el.find_element(css: '.author').attribute('textContent')This information can then be stored in an array. Put together, this is how the code looks like at this stage:
quotes = []
quote_elements = driver.find_elements(css: '.quote')
quote_elements.each do |quote_el|
quote_text = quote_el.find_element(css: '.text').attribute('textContent')
author = quote_el.find_element(css: '.author').attribute('textContent')
quotes << [quote_text, author]
endAnother benefit of using an array to store the scraped public data is that it can be easily saved to a CSV file.
Handling pagination
Our example website has a button to the next page, meaning that we can create a selector that looks for the next button. Once the button is located, the click() function can be called in to press it. On the last page, the next button won’t be found, causing an error.
A while-true loop can be used to scrape the data. The loop will be terminated using a begin-rescue-end block as follows:
quotes = []
while true do
quote_elements = driver.find_elements(css: '.quote')
quote_elements.each do |quote_el|
quote_text = quote_el.find_element(css: '.text').attribute('textContent')
author = quote_el.find_element(css: '.author').attribute('textContent')
quotes << [quote_text, author]
end
begin
driver.find_element(css: '.next >a').click
rescue
break # Next button not found
end
endCreating a CSV file
To create a CSV file, the same approach discussed in the earlier section can be used.
Create the CSV file with header information. Run a loop over all the quotes and save it as a row:
require 'csv'
CSV.open('quotes.csv', 'w+', write_headers: true,
headers: %w[Quote Author]) do |csv|
quotes.each do |quote|
csv << quote
end
endNote that loading data into memory and then writing it might not be the most optimal approach unless you're absolutely sure about your script. Write as you scrape instead to ensure more consistency.
That’s all! You have successfully created a web scraper for extracting public data from dynamic sites and saved the data into a CSV file.
Conclusion
Web scraping with Ruby is all about finding and choosing the right gem. Considerable amounts of gems are developed to cover all steps of the web scraping process, from sending HTML requests to creating CSV files. Ruby’s gems, such as HTTParty and Nokogiri, are perfectly suitable for static web pages with constant URLs. For dynamic web pages, Selenium works great, while Kimurai is the go-to gem for older versions of Ruby as it's conveniently based on Nokogiri.
You can click here to find the complete code used in this article for your convenience.
Building your own web scraper has its challenges, which grow with scale, so for such cases, we recommend taking a look at one of our Scraper API solutions dedicated to web data extraction. And if you want to know more on how to scrape the web using other programming languages, check some of our other articles, such as Web Scraping with JavaScript, Web Scraping with Java, C# Web Scraping, and Python Web Scraping Tutorial.
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.
About the author

Augustas Pelakauskas
Former Senior Technical Copywriter
Augustas Pelakauskas was a Senior Technical Copywriter at Oxylabs. Coming from an artistic background, he is deeply invested in various creative ventures - the most recent being writing. After testing his abilities in freelance journalism, he transitioned to tech content creation. When at ease, he enjoys the sunny outdoors and active recreation. As it turns out, his bicycle is his fourth-best friend.
All information on Oxylabs Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Oxylabs Blog or any third-party websites that may be linked therein. Before engaging in scraping activities of any kind you should consult your legal advisors and carefully read the particular website's terms of service or receive a scraping license.
Related articles

Cheerio vs. Puppeteer: Which Should You Use for Web Scraping?

Shinthiya Nowsain Promi
2026-06-23



List Crawling in Python: Tools, Tips, and Techniques

Danielė Virinaitė
2026-06-17

Get the latest news from data gathering world
Scale up your business with Oxylabs®
Proxies
Advanced proxy solutions
Data Collection
Datasets
Resources
Innovation hub
Forget about complex web scraping processes
Choose Oxylabs' advanced web intelligence collection solutions to gather real-time public data hassle-free.